实操通过~~~~
本文章包括单master节点集群部署和多master节点集群部署,如果环境为多master节点集群部署,在K8S初始化环节,跳到多master节点集群部署章节实施
单master节点集群部署
1、安装环境介绍
安装k8s集群环境,需要3台主机,学习环境4核8G内存,500GB磁盘即可满足要求。这里采用centos7.9系统。
主机名/IP 用途
k8smaster(10.16.213.221) k8s集群的master节点
k8snode1(10.16.213.222) k8s集群的work节点1
k8snode2(10.16.213.223) k8s集群的work节点22、升级内核 #安装新内核(所有节点都执行下面步骤)
CentOS 7系系统默认内核也可以部署,该步可以不执行
[root@master1 kernel]# wget https://elrepo.org/linux/kernel/el7/x86_64/RPMS/kernel-lt-5.4.114-1.el7.elrepo.x86_64.rpm
[root@master1 kernel]# wget https://elrepo.org/linux/kernel/el7/x86_64/RPMS/kernel-lt-devel-5.4.114-1.el7.elrepo.x86_64.rpm
[root@master1 kernel]# yum -y install kernel-lt-5.4.114-1.el7.elrepo.x86_64.rpm kernel-lt-devel-5.4.114-1.el7.elrepo.x86_64.rpm
#调整默认内核启动
[root@master1 kernel]# grub2-set-default "CentOS Linux (5.4.114-1.el7.elrepo.x86_64) 7 (Core)"#检查是否修改正确并重启系统
[root@master1 kernel]# grub2-editenv list
[root@master1 kernel]# reboot3、开启IPVS支持(所有节点都执行下面步骤)
创建/etc/sysconfig/modules/ipvs.modules文件,内容如下:
#!/bin/bash
ipvs_modules="ip_vs ip_vs_lc ip_vs_wlc ip_vs_rr ip_vs_wrr ip_vs_lblc ip_vs_lblcr ip_vs_dh ip_vs_sh ip_vs_fo ip_vs_nq ip_vs_sed ip_vs_ftp nf_conntrack"
for kernel_module in ${ipvs_modules}; do
/sbin/modinfo -F filename ${kernel_module} > /dev/null 2>&1
if [ $? -eq 0 ]; then
/sbin/modprobe ${kernel_module}
fi
done最后,执行如下命令使配置生效:
[root@master1 kernel]# chmod 755 /etc/sysconfig/modules/ipvs.modules
[root@master1 kernel]# sh /etc/sysconfig/modules/ipvs.modules
[root@master1 kernel]# lsmod | grep ip_vs4、关闭防火墙、selinux(所有节点都执行下面步骤)
K8s集群每个节点都需要关闭防火墙,执行如下操作:
[root@master1 kernel]# systemctl stop firewalld && systemctl disable firewalld
[root@master1 kernel]# setenforce 0
[root@master1 kernel]# sed -i "s/SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config接着,还需要关闭系统的交换分区,执行如下命令:
[root@master1 kernel]# swapoff -a
[root@master1 kernel]# cp /etc/fstab /etc/fstab.bak
[root@master1 kernel]# cat /etc/fstab.bak | grep -v swap > /etc/fstab然后,还需要修改iptables设置,在/etc/sysctl.conf中添加如下内容:
vm.swappiness = 0
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
[root@master1 kernel]# sysctl -p5、主机名本地解析配置(所有节点都执行下面步骤)
若主机名采用规范的域名格式并解析,可以不执行该步骤
每个主机的主机名以及IP地址都在上面环境介绍中给出来了,根据这些信息,在每个k8s集群节点添加如下主机名解析信息,将这些信息添加到每个集群节点的/etc/hosts文件中,主机名解析内容如下:
127.0.0.1 localhost
10.16.213.221 k8smaster
10.16.213.222 k8snode1
10.16.213.223 k8snode26、安装docker环境(所有节点都执行下面步骤)
所有节点都需要安装docker,每个节点都需要使docker开机自启,执行如下命令
# yum install -y yum-utils device-mapper-persistent-data lvm2
# yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# yum makecache fast
# yum install -y docker-ce
# systemctl restart docker
# systemctl enable docker
# yum update -y containerd
# vi /etc/containerd/config.toml
#disabled_plugins = ["cri"] ## 注释该配置
# systemctl restart containerd
# systemctl enable containerd
# docker version
# containerd -v7、安装Kubeadm、kubelet、kubectl工具(所有master节点执行下面步骤)
在确保系统基础环境配置完成后,现在我们就可以来安装 Kubeadm、kubelet了,我这里是通过指定yum 源的方式来进行安装,使用阿里云的源进行安装:
# cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0 repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF然后安装 kubeadm、kubelet、kubectl,可先查询可安装的版本,然后指定版本进行安装。
[root@k8smaster containerd]# yum list kubelet
kubelet.x86_64 1.24.3-0 kubernetes
[root@k8smaster ~]# yum install -y kubelet kubeadm kubectl
[root@k8smaster ~]# systemctl daemon-reload && systemctl enable kubelet8、初始化k8s集群
初始化集群前,生产环境建议先做证书有效期修改(默认有效期为1年,忒短了)
参考:Kubernetes--1.24.3集群更换100年证书
如果在镜像拉取或初始化过程中报如下错误
failed to pull image "k8s.gcr.io/kube-apiserver:v1.24.3": output: time="2022-08-03T10:45:49+08:00" level=fatal msg="unable to determine image API version: rpc error: code = Unavailable desc = connection error: desc = \"transport: Error while dialing dial unix /var/run/containerd/containerd.sock: connect: no such file or directory\""
, error: exit status 1
To see the stack trace of this error execute with --v=5 or higherkubeadm config images pull
[init] Using Kubernetes version: v1.24.3
[preflight] Running pre-flight checks
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR CRI]: container runtime is not running: output: time="2022-08-03T10:23:56+08:00" level=fatal msg="unable to determine runtime API version: rpc error: code = Unavailable desc = connection error: desc = \"transport: Error while dialing dial unix /var/run/containerd/containerd.sock: connect: no such file or directory\""
, error: exit status 1
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
# vi /etc/containerd/config.toml
#disabled_plugins = ["cri"]
# systemctl restart containerd禁用上述配置并重启服务即可
如果服务器重启或者kubelet服务重启,kubelet服务启动失败,也需要关注 disabled_plugins = ["cri"] 选项是否关闭,若启用了,则需要注释该选项后,重启 containerd 服务,再启动kubelet服务,关注服务状态及log。
执行如下命令:
[root@master ~]# kubeadm config print init-defaults
[root@master ~]# kubeadm config images list
[root@master ~]# kubeadm config images list --kubernetes-version=v1.24.3 --image-repository registry.aliyuncs.com/google_containers
[root@master ~]# kubeadm config images pull --kubernetes-version=v1.24.3 --image-repository registry.aliyuncs.com/google_containers其中:
第一个命令用来查看安装k8s的相关信息,主要是安装源和版本。
第二条命令是查询需要的镜像,从输出可在,默认是从k8s.gcr.io这个地址下载镜像,此地址国内无法访问,因此需要修改默认下载镜像的地址。
第三条命令是设置k8s镜像仓库,查看一下需要下载的镜像都有哪些。
第四条命令是拉取镜像
由此可知,通过kubeadm初始化集群,需要这7个镜像,由于gcr无法访问,因此,我将这些镜像统一使用阿里云。
接着,在 master 节点配置 kubeadm 初始化文件,可以通过如下命令导出默认的初始化配置:
[root@master ~]# kubeadm config print init-defaults > kubeadm-init.yaml然后根据我们自己的需求修改配置,这里修改的有advertiseAddress、criSocket、name、imageRepository 的值,同时,添加了kube-proxy的模式为ipvs,,并且,需要注意的是,由于我们使用的containerd作为运行时,所以在初始化节点的时候需要指定cgroupDriver为systemd。
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 10.16.213.221 ## 本机可被访问的IP
bindPort: 6443
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
imagePullPolicy: IfNotPresent
name: k8smaster ## 设备的hostname
taints: null
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /data/etcd
imageRepository: k8s.gcr.io
kind: ClusterConfiguration
kubernetesVersion: 1.24.3
networking:
dnsDomain: cluster.local
podSubnet: 192.168.0.0/16
serviceSubnet: 172.16.0.0/16
scheduler: {}
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: "ipvs"
---
kind: KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
cgroupDriver: systemd
在保证所需要的镜像都可以正常下载后,使用上面的配置文件进行初始化:
关闭iptables,否则可能报如下错误:
[kubelet-check] Initial timeout of 40s passed.
error execution phase upload-config/kubelet: Error writing Crisocket information for the control-plane node: nodes "k8smaster" not found
[root@k8smaster ~]# service iptables stop
[root@k8smaster ~]# kubeadm init --config=kubeadm-init.yaml --v=5 | tee ~/kubeadm-init.log
如果初始化失败,可以执行如下命令后重新初始化
# kubeadm reset
# rm -rf /etc/kubernetes/ ~/.kube/ /data/etcd /var/lib/cni/ ~/kubeadm-init.log初始化完成,根据提示,在master节点执行如下操作
[root@k8smaster ~]# mkdir -p $HOME/.kube
[root@k8smaster ~]# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@k8smaster ~]# chown $(id -u):$(id -g) $HOME/.kube/config为了使用更便捷,启用 kubectl 命令的自动补全功能。
# yum install bash-completion -y
# source /usr/share/bash-completion/bash_completion
# source <(kubectl completion bash)
# echo "source <(kubectl completion bash)" >> ~/.bashrc现在kubectl可以使用了
9、添加集群节点
初始化集群的操作是在master节点完成的,接下来,要将work节点加入到集群中,首先需要在每个node节点上执行基础配置工作,主要有关闭防火墙和selinux、禁用swap、配置主机名解析、启动网络桥接功能以及启动kubeket服务并设置开机自启,这些已经在前面介绍过,这里不再多说了。
下面介绍下如何添加nodes到集群中,执行如下命令:
[root@master ~]# kubeadm join 10.16.213.221:6443 --token bnefy8.d79yn6ylxlk7k8hr --discovery-token-ca-cert-hash sha256:eaa17f4b308e9406891f85f664c0d2c97a49bd9e963f64c9453b7042509e106c这里的–token来自前面kubeadm init输出提示,如果当时没有记录下来可以通过如下命令找回, token是有24小时有效期的:
[root@master ~]# kubeadm token create --ttl 0 --print-join-command执行成功后运行 get nodes 命令
[root@k8smaster ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8smaster NotReady control-plane,master 29m v1.21.0
k8snode1 NotReady <none> 28m v1.21.0
k8snode2 NotReady <none> 28m v1.21.0可以看到是,两个节点都是NotReady 状态,这是因为还没有安装网络插件。
10、安装网络插件
接下来安装网络插件。网络插件可以选择calico和flannel,这里我们使用calico。
[root@k8smaster ~]# wget --no-check-certificate https://docs.projectcalico.org/manifests/calico.yaml安装calico网络插件
[root@k8smaster ~]# kubectl apply -f calico.yaml此插件的安装过程,需要下载三个镜像文件,下载完成,网络插件即可正常工作。等网络插件镜像下载完成以后,看到node的状态会变成ready,执行如下命令查看:
[root@k8smaster ~]# kubectl get nodes如果发现某个节点还是处于NotReady状态,可以重启此节点的kubelet服务,然后此节点就会重新下载需要的镜像。
最后,执行如下命令,查看pod状态:
[root@master ~]# kubectl get pods -n kube-system如果状态中有 CrashLoopBackOff 相关的,使用如下命令查看日志
# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-6766647d54-8fx4l 0/1 Pending 0 142m
calico-node-6pdbx 0/1 Init:CrashLoopBackOff 31 (2m14s ago) 142m
calico-node-lklf7 0/1 Init:CrashLoopBackOff 31 (2m48s ago) 142m
calico-node-lvx9x 0/1 Init:CrashLoopBackOff 31 (3m34s ago) 142m
coredns-6d4b75cb6d-l254l 0/1 Pending 0 147m
coredns-6d4b75cb6d-vv9jd 0/1 Pending 0 147m
etcd-w58v.game.corp.qihoo.net 1/1 Running 0 147m
kube-apiserver-w58v.game.corp.qihoo.net 1/1 Running 0 147m
kube-controller-manager-w58v.game.corp.qihoo.net 1/1 Running 5 147m
kube-proxy-k6v67 0/1 CrashLoopBackOff 33 (2m59s ago) 146m
kube-proxy-r2hx7 0/1 CrashLoopBackOff 33 (2m23s ago) 146m
kube-proxy-xpmlc 0/1 CrashLoopBackOff 38 (2m29s ago) 147m
kube-scheduler-w58v.game.corp.qihoo.net 1/1 Running 5 147m
# kubectl logs -f -n kube-system kube-proxy-k6v67 -c kube-proxy
E0715 10:05:40.822913 1 run.go:74] "command failed" err="failed complete: unrecognized feature gate: SupportIPVSProxyMode"
根据报错排查问题,直到node及pod状态正常
# kubectl get nodes
NAME STATUS ROLES AGE VERSION
w58v.game.corp.qihoo.net Ready control-plane 11m v1.24.3
w59v.game.corp.qihoo.net Ready <none> 9m44s v1.24.3
w60v.game.corp.qihoo.net Ready <none> 9m33s v1.24.3
# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-6766647d54-9nbhm 1/1 Running 0 9m
calico-node-447pz 1/1 Running 0 9m
calico-node-t9nc4 1/1 Running 0 9m
calico-node-v7dwb 1/1 Running 0 9m
coredns-6d4b75cb6d-48wwq 1/1 Running 0 11m
coredns-6d4b75cb6d-dg2x5 1/1 Running 0 11m
etcd-w58v.game.corp.qihoo.net 1/1 Running 1 11m
kube-apiserver-w58v.game.corp.qihoo.net 1/1 Running 1 11m
kube-controller-manager-w58v.game.corp.qihoo.net 1/1 Running 6 11m
kube-proxy-5zrd6 1/1 Running 0 11m
kube-proxy-k5njh 1/1 Running 0 9m38s
kube-proxy-sgdbw 1/1 Running 0 9m49s
kube-scheduler-w58v.game.corp.qihoo.net 1/1 Running 6 11m部署 metrics-server
Metrics Server是一个集群范围内的资源数据集和工具,同样的,metrics-server也只是显示数据,并不提供数据存储服务,主要关注的是资源度量API的实现,比如CPU、文件描述符、内存、请求延时等指标,metric-server收集数据给k8s集群内使用,如kubectl,hpa,scheduler等。
Metrics Server从Kubelet收集资源指标,并通过Metrics API在Kubernetes apiserver中公开它们,以供Horizontal Pod Autoscaler(HPV)和Vertical Pod Autoscaler(VPA)使用。Metrics API也可以通过访问kubectl top,从而更容易调试自动缩放管道。
Metrics Server不适用于非自动缩放目的。例如,不要使用它来将指标转发给监控解决方案,或作为监控解决方案指标的来源。在这种情况下,请直接从Kubelet/metrics/resource端点收集指标。
Metrics Server提供:
1、适用于大多数集群的单一部署
2、快速自动缩放,每15秒收集一次指标
3、资源效率,集群中每个节点使用1 mili 的CPU核心和2 MB的内存
4、可扩展支持多达5,000 个节点集群
https://github.com/kubernetes-sigs/metrics-server
# kubectl apply -f components.yaml
or
# kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.6.1/components.yaml如果运行报 x509: cannot validate certificate 错误,需要在部署里增加 --kubelet-insecure-tls 参数
# vi components.yaml
containers:
- args:
- --cert-dir=/tmp
- --secure-port=10250
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
- --kubelet-insecure-tlspod启动完毕后,执行如下指令测试
# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8smaster 1720m 10% 1844Mi 5%
k8snode1 1525m 9% 1861Mi 5%
k8snode2 1596m 9% 1190Mi 3% 若有报错,运行 kubectl get apiservices v1beta1.metrics.k8s.io -o yaml 查看status: message 里的报错内容
11、在k8s集群中安装kubernetes-dashboard
kubernetes-dashboard是k8s的UI看板,可以查看、编辑整个集群状态。
部署思路
1、通过nginx-ingress的方式来对外提供访问
优点:主流,安全,方便管理
缺点:配置相当复杂麻烦,不熟悉的同学会晕圈
2、通过service的NodePort的方式来对外提供访问
优点:部署方便,快捷
缺点:NodePort端口过多造成不易管理的问题,不安全
这里我采用的是第二种NodePort的方式(生产环境推荐第一种方式)。
可从https://github.com/kubernetes/dashboard/下载最新的dashboard/资源文件,然后进行安装。
下载下来的文件名为recommended.yaml,编辑一下,通过NodePort方式部署访问。
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
type: NodePort #新增,默认为ClusterIP模式
ports:
- port: 443
targetPort: 8443
nodePort: 30443 #新增,对外暴露的端口,valid ports is 30000-32767
selector:
k8s-app: kubernetes-dashboard
如果不添加type或者nodePort不在范围内,会有如下报错:
The Service "kubernetes-dashboard" is invalid: spec.ports[0].nodePort: Forbidden: may not be used when `type` is 'ClusterIP'
The Service "kubernetes-dashboard" is invalid: spec.ports[0].nodePort: Invalid value: 10443: provided port is not in the valid range. The range of valid ports is 30000-32767
执行如下命令进行安装:
# kubectl apply -f recommended.yaml
namespace/kubernetes-dashboard created
serviceaccount/kubernetes-dashboard created
service/kubernetes-dashboard created
secret/kubernetes-dashboard-certs created
secret/kubernetes-dashboard-csrf created
secret/kubernetes-dashboard-key-holder created
configmap/kubernetes-dashboard-settings created
role.rbac.authorization.k8s.io/kubernetes-dashboard created
clusterrole.rbac.authorization.k8s.io/kubernetes-dashboard created
rolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created
clusterrolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created
deployment.apps/kubernetes-dashboard created
service/dashboard-metrics-scraper created
deployment.apps/dashboard-metrics-scraper created安装完成后,执行如下命令,查看kubernetes-dashboard的访问端口:
[root@k8smaster ~]# kubectl get svc -n kubernetes-dashboard
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
dashboard-metrics-scraper ClusterIP 10.98.184.182 <none> 8000/TCP 150m
kubernetes-dashboard NodePort 10.100.209.10 <none> 443:30443/TCP 150m此时,查看dashboard部署在那个node上(kubectl get pod -A -o wide),用node的ip加上30443端口访问kubernetes-dashboard 。
访问dashboard需要认证,因此还需要创建一个认证机制,执行如下命令,创建一个ServiceAccount用户admin-user 在 kubernetes-dashboard空间:
# vi dashboard-adminuser.yaml
apiVersion: v1 kind: ServiceAccount metadata: name: admin-user namespace: kubernetes-dashboard --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: admin-user roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: - kind: ServiceAccount name: admin-user namespace: kubernetes-dashboard
# kubectl apply -f dashboard-adminuser.yaml建立token:
# kubectl -n kubernetes-dashboard create token admin-user
此命令输出中,就是令牌,复制出来保存。有了令牌后,就可以在dashboard选择令牌登录了。
多master节点集群部署
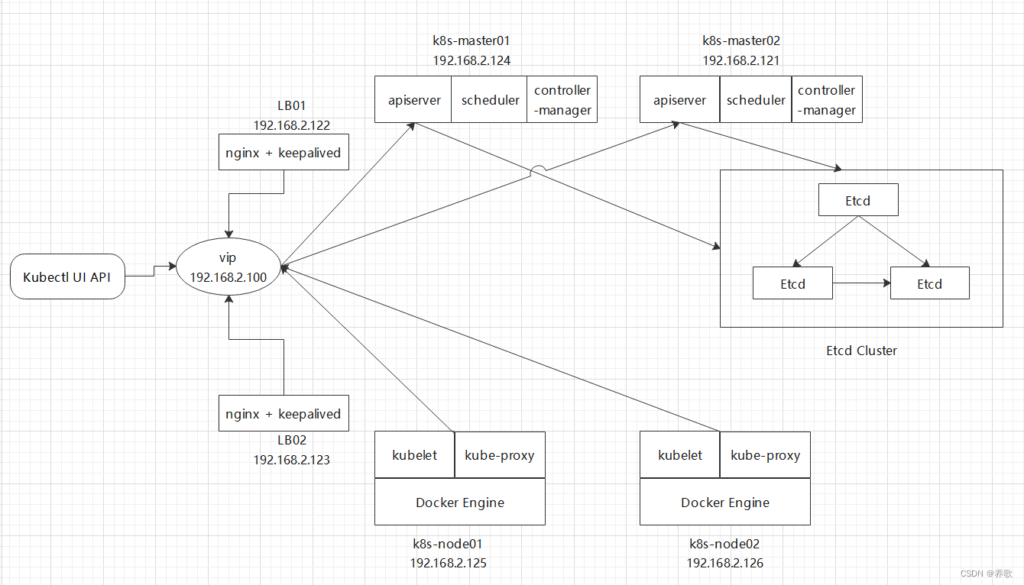
网上找的示例图,供参考
单master节点集群部署情况下,master的可靠性是个问题,一旦master设备故障,将会导致整个集群故障,因此需要对master做多节点部署,提升master的可靠性
假设规划2台master,另一台master为k8smaster-2:10.16.213.220
特别注意:设置几台设备为master,建议提前规划好!!!
配置VIP:10.16.10.10
VIP的配置,可以使用既有服务获取(例如云服务申请的SLB),也可以使用keepalived自主配置(适用于自建网络)
在k8smaster-1上执行:
前面设备环境的配置雷同,在做k8s集群初始化时,使用如下配置初始:
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 10.16.213.221
bindPort: 6443
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
imagePullPolicy: IfNotPresent
name: w61v.game.corp.qihoo.net
taints: null
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /data/etcd
imageRepository: k8s.gcr.io
kind: ClusterConfiguration
kubernetesVersion: 1.24.3
networking:
dnsDomain: cluster.local
podSubnet: 192.168.0.0/16
serviceSubnet: 172.16.0.0/16
scheduler: {}
controlPlaneEndpoint: 10.16.10.10:6443 ## VIP地址
apiServer: ## 将VIP、MasterIPs添加到列表里
certSANs:
- 10.16.10.10
- 10.16.206.140
- 10.16.204.69
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: "ipvs"
---
kind: KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
cgroupDriver: systemd执行初始化操作
# kubeadm init --config=kubeadm-init.yaml --v=5 | tee ~/kubeadm-init.log
......
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join 10.16.10.10:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:1262fce918197e048be68ae5f42e9acb9eedfd7c5c5fa9473fd7948d65875c5f \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 10.16.10.10:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:1262fce918197e048be68ae5f42e9acb9eedfd7c5c5fa9473fd7948d65875c5f 对比单master集群部署,多master集群部署初始化,会有master节点的加入方式,并且apiserver的ip为VIP
将相关证书打包传送到k8smaster-2设备
https://kubernetes.io/zh-cn/docs/setup/production-environment/tools/kubeadm/high-availability/
--upload-certs 标志用来将在所有控制平面实例之间的共享证书上传到集群。 如果正好相反,你更喜欢手动地通过控制平面节点或者使用自动化工具复制证书, 请删除此标志并参考如下部分证书分配手册。
根据官方文档说明,在初始化的时候添加 --upload-certs 参数,可以免除手动证书分发的操作。(未验证)
# cd /etc/kubernetes/pki
tar czvf pki.tar.gz ca.* sa.* front-proxy-ca.* etcd/ca.*
scp pki.tar.gz quwenqing@k8smaster-2:~登录到k8smaster-2设备
# cd /etc/kubernetes/pki
tar xzvf /home/quwenqing/pki.tar.gz执行添加指令:
# kubeadm join 10.16.10.10:6443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:1262fce918197e048be68ae5f42e9acb9eedfd7c5c5fa9473fd7948d65875c5f --control-plane --v=5
This node has joined the cluster and a new control plane instance was created:
* Certificate signing request was sent to apiserver and approval was received.
* The Kubelet was informed of the new secure connection details.
* Control plane label and taint were applied to the new node.
* The Kubernetes control plane instances scaled up.
* A new etcd member was added to the local/stacked etcd cluster.
To start administering your cluster from this node, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Run 'kubectl get nodes' to see this node join the cluster.将配置放到家目录
# mkdir -p $HOME/.kube
# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
# chown $(id -u):$(id -g) $HOME/.kube/config
# kubectl get node
NAME STATUS ROLES AGE VERSION
k8smaster-1 NotReady control-plane 12m v1.24.3
k8smaster-2 NotReady control-plane 102s v1.24.3继续添加其他master或node节点
# kubectl get node
NAME STATUS ROLES AGE VERSION
k8smaster-1 NotReady control-plane 12m v1.24.3
k8smaster-2 NotReady control-plane 102s v1.24.3
k8snode-1 NotReady 3m11s v1.24.3 在k8smaster-1上继续添加calico网络插件
其他步骤雷同单master集群部署步骤
参考:https://blog.51cto.com/ixdba/2857919